If diffusion is so much faster, why isn’t Google using it in big cloud-based Gemini models? Google has experimented with this, but there are a few drawbacks to text diffusion, including a higher error rate. In image diffusion models, a single badly predicted pixel doesn’t make the image useless, but language is discreet. An equivalent error in text can make a block of tokens meaningless and force you to start over to get a better output. Diffusion models also waste resources when the desired output is only a few tokens long. They have to do a lot more parallel work to whittle down to a few tokens that an autoregressive model does from beginning to end in just five steps.
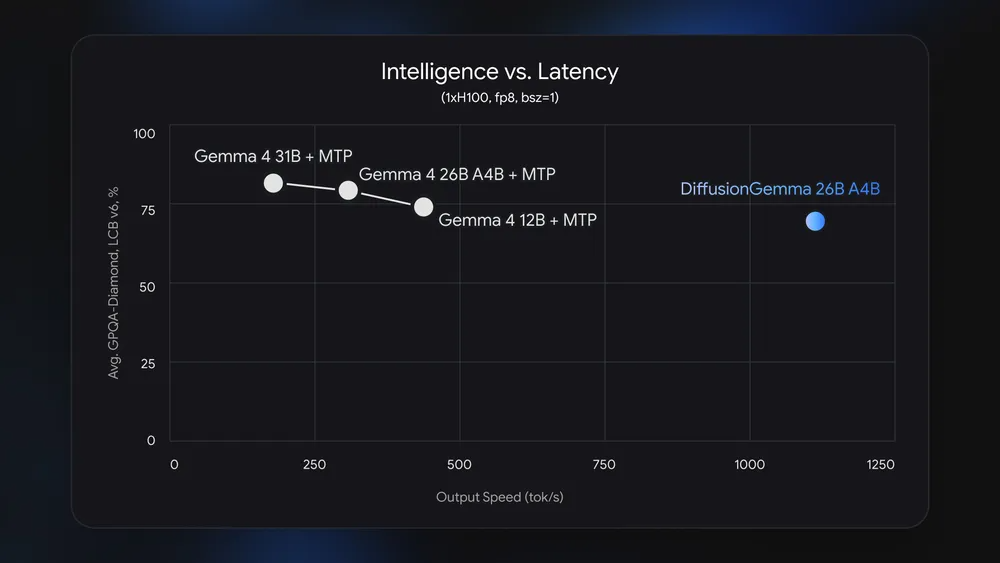
DiffusionGemma is about as capable as other Gemma models, but it’s much faster.
Credit:
Google
<figcaption>
<div>
<p>
DiffusionGemma is about as capable as other Gemma models, but it’s much faster.
<span>
Credit:
Google
</span>
</p>
The efficiency gain for local processing makes this an appealing avenue of experimentation, though. In the cloud, autoregressive models can batch large numbers of compute jobs from multiple users so they’re always churning out tokens, and the high bandwidth memory (HBM) used in these systems can move data around much more efficiently.
Conversely, local AI encounters wasted compute cycles due to lower memory bandwidth and idle time. Diffusion models can make more efficient use of available compute, but this isn’t the only way. Google also recently began implementing Multi-Token Prediction (MTP) drafters, which use otherwise wasted compute cycles to predict possible tokens to increase speed. But diffusion is even faster than the MTP versions of Gemma.
Google stresses that DiffusionGemma is experimental, but it’s available under the same Apache 2.0 license as all the other fourth-generation Gemma models. You can download the model weights today from Hugging Face. Google says it worked with Nvidia to ensure DiffusionGemma was optimized for a variety of setups, including high-end RTX GPUs (quantized) and enterprise systems like the H100 or DGX Spark platform.